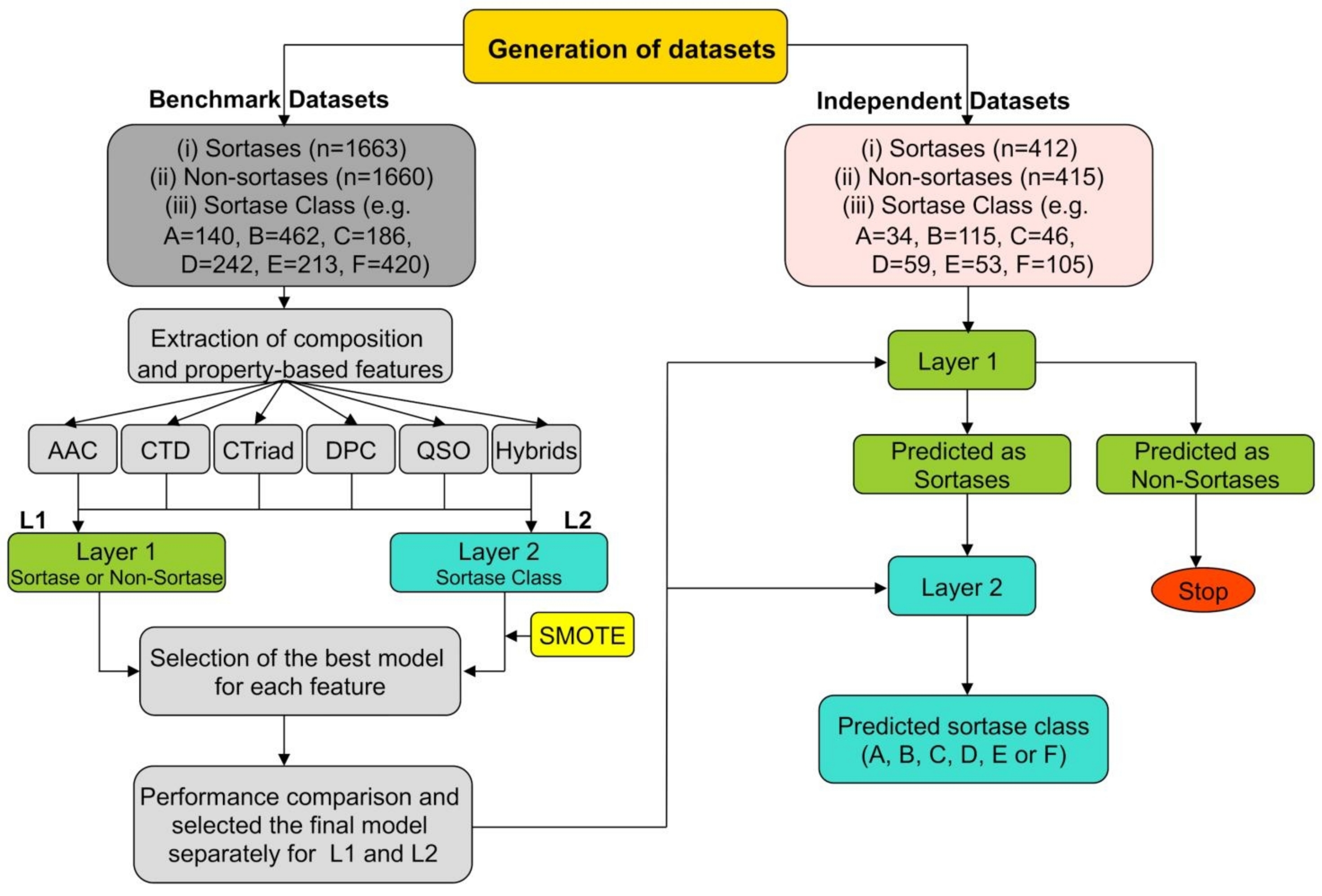
SortPred consists of two separate prediction layers. Both the benchmark and independent datasets for Layer 1 consists of sortases and non-
sortases, where as Layer 2 comprises the sequences representing each sortase class. In both
these layers, five composition and property-based features (AAC, CTD, CTriad, DPC &
QSO) and their hybrids are utilized in a 10-fold cross validation using RF to select the best
models from each layer. For Layer 2 SMOTE algorithm is used to handle the imbalance data
during cross-validation. For each layer, the performance of the selected models are evaluated
on the independent datasets separately. Finally, if the sequence is predicted to be as a sortase
enzyme, this information is passed to Layer 2 for predicting the sortase class.
Reference
SortPred: The first machine learning based predictor to identify bacterial sortases and their classes using sequence-derived information (Manuscript Submitted). [Please cite this paper if you find SortPred useful in your research]